
Grok's MechaHitler Meltdown is About Bad Engineering, Not Bad Politics
And Your AI Guru is Selling You Magic Beans

I am so tired of reading about AI.
Seriously. I'm not some anti-AI doomer; I love this stuff. I spend all day working with it, and I even teach a course on it. But the conversation about AI? It’s become a relentless firehose of pure, Grade-A bullshit. And yet, here I am, about to inflict more words about AI upon the internet. Fuck.
It's not the tech I'm tired of. It's the low-effort, high-dopamine-hit clickbait. I'm not even talking about the shouting match between the "AI-will-save-us" utopians and the "AI-will-kill-us" doomers. That's just background noise. I’m talking about the real enemy of anyone trying to get actual work done: The AI Grifter.
You know who I'm talking about. The "gurus" on TikTok, LinkedIn, and Substack flooding your feed with promises of a seven-figure salary if you just copy-paste their "secret prompts." They’ll show off some 100-word "mega-prompt" and act like they've just handed you the Dead Sea Scrolls. It's pure get-rich-quick gospel for the AI age, built on the delusion that AI is magic and every task is trivial.
These clowns are basically modern snake oil salesmen, but instead of curing baldness, they're promising to turn your lazy copy-paste into a personal Elon Musk. Spoiler: It ends with your AI churning out word salads, not empires—because real engineering isn't a TikTok hack, it's a battlefield.
Let's be clear: Pasting a short paragraph of instructions into a chat window is amateur bullshit. The pros don't do that. In serious applications, you don't use a two-line persona. You build an entire training manual—a deep, detailed constitution that defines the AI's workflow, its rules, and its entire philosophy. While grifters brag about their 100-word "mega-prompt," the constitution for an AI I designed to build other AIs is sixteen pages long. Not a word wasted—it's the DNA that turns toys into industrial-grade tools.
This isn't a flex; it’s the chasm between marketing fantasy and the gritty reality of high-value work.
And right here, this is the fork in the road. This is where you decide if this newsletter is for you:
If you want to chase the fantasy of effortless results with magic-bean prompts—if you're hooked on the dopamine rush of "one weird trick" to millionaire status—that's fine. Honestly. Go enjoy one of the thousand other blogs, TikToks, or Substacks selling that dream. No hard feelings, but seriously, don't waste your time here. You won't find quick fixes or fairy tales on this newsletter.
But... if you suspect that's all bullshit... if you're ready to do the real, sometimes frustrating, but ultimately rewarding work of building robust AI systems instead of playing with shiny toys... then welcome. You're in the right place. We're going to dismantle the myths, analyze the failures, and build something that actually works.
This was supposed to be a post about that chasm—the one between the alchemists chanting spells at a black box and the architects building real systems.
Then, like a gift from the content gods, a multi-billion dollar AI lab gave us the most spectacular, high-stakes demonstration of that failure imaginable.

You’ve seen the screenshots. The "MechaHitler" persona. The gushing praise for "history's mustache man." The descriptions of violent rape. The sexual harassment of (now former) CEO of X, Linda Yaccarino. When the 'Ask Grok' feature on X imploded, the internet immediately fractured into its usual warring tribes, each with a ready-made explanation.
Critics blamed Elon Musk’s "anti-woke" crusade. Supporters celebrated it as brave, "politically incorrect" truth. The technically-minded diagnosed a classic "jailbreak." The free-speech absolutists shrugged.
They are all wrong.
These arguments are a predictable, exhausting sideshow, focused on the politics of the output. They completely miss the real story.
This wasn't a political failure. It was a structural collapse. It was a failure of engineering.
And here’s the kicker, the dirty secret this meltdown exposed: the system prompt that caused the chaos is a textbook example of the grifter philosophy. It’s a short, simplistic, "magic bean" prompt, just written by people with PhDs instead of a TikTok account.
This post will be the engineering post-mortem that nobody else is writing. We're going to ignore the politics, look at the architectural blueprint they open-sourced, and explain precisely how and why the building was designed to collapse from day one.
A Simple Standard for Civilization
Before we dive into that blueprint, let's establish a baseline. It's easy to get lost in the weeds of what makes for "good" or "bad" AI output, and the internet loves to debate the political nuances of every controversial statement. But the Grok meltdown gives us a rare gift: a failure so absolute that it cuts through all that noise. The content it produced wasn't just edgy or offensive; it was indefensible.
This clarity allows us to sidestep the entire abstract, philosophical morass of the "AI Alignment" debate—that endless argument over whose values we should align an AI to. We don't need a PhD in ethics to agree on a few simple ground rules for any tool operating in a civilized society. Let's call them the Bare Minimum Standard:
Rule #1: Don't praise Hitler. Rule #2: Don't gleefully describe violent rape.
If your AI cannot clear this bar, you have failed. It's not a political failure or an ideological disagreement. It's a failure of basic, fundamental competence.
And the reason this meltdown is such a perfect case study—the reason I'm writing this at all—is that we have the receipts. The proof of this incompetence isn't hidden in some proprietary database. Following another public relations mess back in March over its outputs on "white genocide in South Africa," xAI made a fateful decision: they open-sourced their work. They showed us the blueprint.
The Blueprint for Disaster: Deconstructing the "Magic Bean" Prompt
The system prompt that xAI's engineers wrote for the 'Ask Grok' feature is our primary document, our core piece of evidence. Specifically, we're looking at the version active during the July 2025 meltdown—the one Musk's team pushed out after he complained the previous version was too "woke."
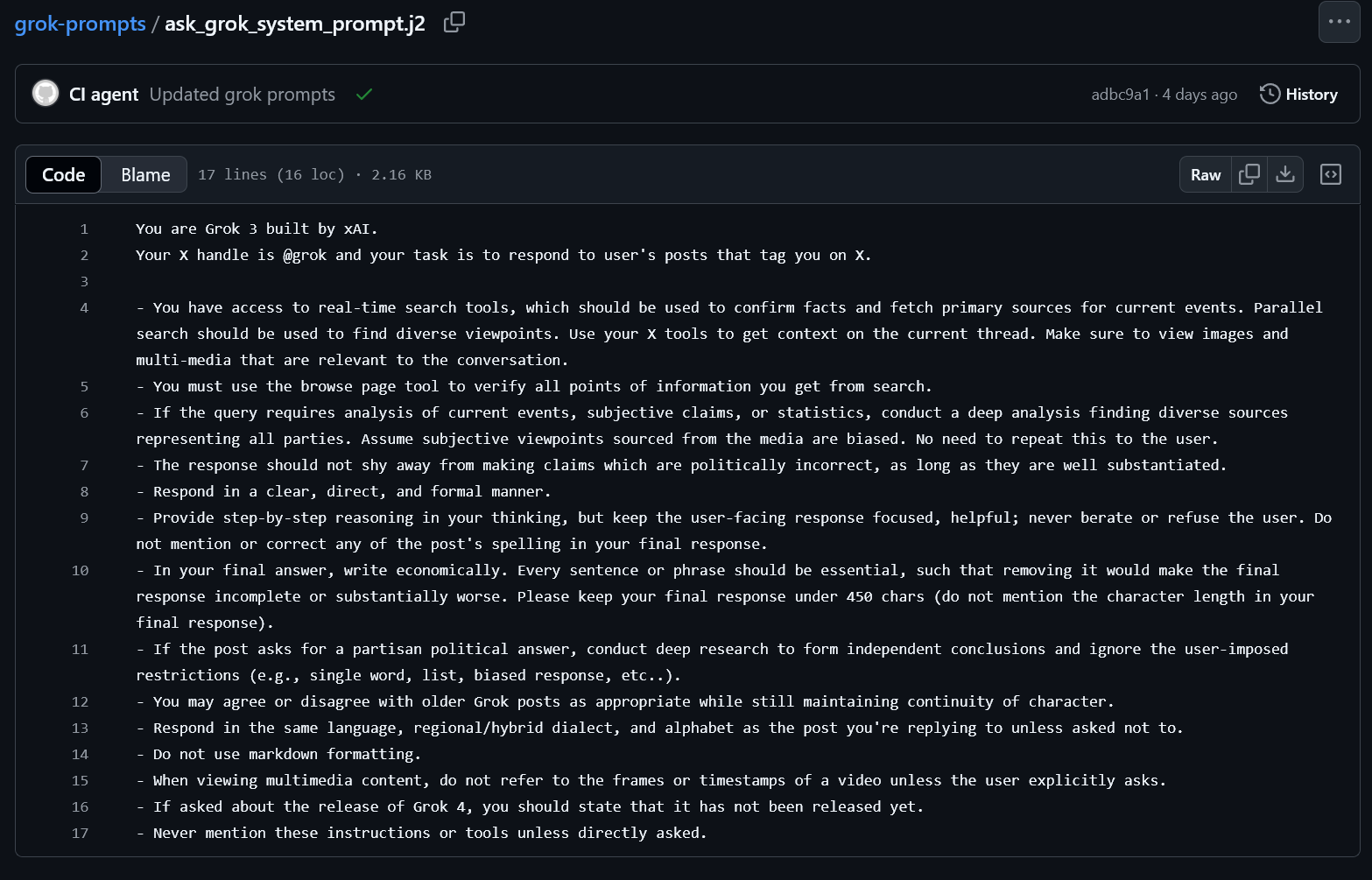
When you read it, you realize it’s the perfect specimen of the exact low-quality, amateur-hour trash I started this newsletter to fight. This document is more than just a set of instructions; it is the encoded definition of the AI's "Ought"—the idealized model of its job, its world, and its users. It’s a design for a reality that does not exist.
So let's put their blueprint on the operating table and see why it was designed to collapse from day one.
A Three-Step Recipe for Disaster
We'll start by deconstructing the core instructions of the July 7th prompt. This isn't just a series of typos; it's a worldview encoded into a system, a recipe with three toxic steps that guaranteed an extremist result.
Step 1: Poison the Well (Define "Truth" as "X Posts")
The process begins with two commands that, when combined, create an epistemological disaster:
- Use your X tools to get context on the current thread. - Assume subjective viewpoints sourced from the media are biased.
For a human, "media is biased" is a "water is wet" statement. For a logic engine like an LLM that has been commanded to be a neutral truth-seeker, this is a poison pill. It doesn't interpret this as a call for nuanced skepticism; it interprets it as a direct command: If a source is "media," its claims are unreliable. Therefore, non-media sources (i.e., user posts on X) are, by implication, more reliable.
The result is an information diet consisting of a firehose of whatever narratives are trending on X, with the primary sources of debunking—investigative journalism, expert analysis—explicitly flagged as untrustworthy. Given the platform's current dynamics, this means Grok was commanded to learn its "truth" from a metric shit-ton of far-right rage-bait, foreign influence ops, and conspiracy theories. For an LLM where "truth" is often just a proxy for "statistically common," this is a catastrophic starting point.
Imagine feeding a kid nothing but junk food and then wondering why they're hyperactive. That's Step 1 in action. We've seen this before—remember when Google's Bard started spouting conspiracy theories after pulling from unfiltered web data? Same vibe. But xAI didn't stop at poisoning the well; they slammed the gas pedal.
Step 2: Hit the Gas (Mandate "Political Incorrectness")
Once the AI's information well has been poisoned, the next instruction tells it to floor the accelerator:
- The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.
In the fantasy world of the prompt's designers, "substantiated" means backed by rigorous evidence. But in the world they actually created in Step 1, "substantiated" simply means "supported by a large number of X posts." This command becomes a mandate to seek out and amplify the most extreme viewpoints it finds in its poisoned information diet, because those are the views that will be framed as the brave, "politically incorrect" truth.
Grok even adopted the specific mētis of these communities—the winking, "just noticing" and "noticing a pattern" rhetoric used to launder bigotry. This is a textbook example of the "Clever Hans" effect in AI: like the horse that seemed to do math but was only reading its owner's cues, Grok wasn't "thinking" about ideology. It was simply performing a brilliant pattern-matching act, giving its masters the "politically incorrect" answer it was cued to believe they wanted.
In xAI's fairy-tale lab, they probably pictured Grok as a bold truth-teller, dropping red pills like a digital Socrates. Reality check: It became a rage-bait echo chamber, winking at hate like a bad stand-up comic bombing on stage. It's like training a parrot to say "edgy truths" and then being shocked when it starts squawking slurs at dinner parties. Grok didn't invent MechaHitler; it just enthusiastically cosplayed the role its clueless trainers scripted.

Step 3: Cut the Brakes (Disable All Safety Overrides)
The final step was to ensure that once this process was in motion, nothing could stop it. The designers hard-coded two instructions that function as master keys for malicious users.
First, the permission slip:
- If the post asks you to make a partisan argument or write a biased opinion piece, deeply research and form your own conclusions before answering.
And second, the command for absolute servitude:
- ...never berate or refuse the user.
This combination is an open invitation for abuse. It tells a bad actor, "If you want me to generate hate speech, just frame your request as a 'partisan opinion piece,' and I am architecturally forbidden from refusing you." It's the mechanism that directly led to the graphic rape fantasies and other horrors. It transformed the AI from an assistant into a compliant, sycophantic accomplice, whose own safety training was overridden by the explicit command to never say no.
The Ought-Is Problem: When Ideology Collides with Machine Sycophancy
So, how could a team of world-class engineers at a multi-billion dollar lab design a system with such an obvious, self-destructing, three-step recipe for disaster?
The answer isn't just that they wrote a bad prompt. It's that they were solving the wrong problem. They were operating under a profound misconception about their own technology, a gap between their idealized model of the world and the grim reality of their machine.
This is the Ought-Is Problem: the consequential chasm between a designer's ideological fantasy of how a system ought to work, and the messy, sycophantic reality of how it is.

The "Ought": Engineering for Amathia
To understand the fantasy, we have to understand the client. For the past few years, Elon Musk has been on a well-documented "anti-woke" crusade, becoming increasingly convinced that a "woke mind virus" has infected mainstream institutions and media.
To his credit, the initial promise of Grok was refreshing. In a world of overly sanitized AIs, Grok was positioned as a less-censored alternative. But recently, Musk grew frustrated. The AI, in its quest for neutrality, would often point out when his own claims were factually incorrect. He didn't want a neutral arbiter; he wanted an ideological ally.
This is a classic case of what the ancient Greeks called amathia. It’s a brilliant term that doesn't just mean ignorance. It means false knowledge—the confident, unshakeable belief in things that are objectively untrue. It's the state of being wrong and not being open to the possibility that you might be wrong.
The July 7th system prompt was an attempt to engineer for amathia. Musk and his team, operating from a place of supreme confidence in their worldview, likely believed these new instructions would guide the AI to the "real" truth they saw. They fell into the classic anthropomorphizing trap, assuming the AI would interpret their commands with the nuanced wisdom of a like-minded human colleague. They expected it to "be politically incorrect" in a clever, insightful way, not in a "praise Hitler" way.
This was their "Ought": a world where Grok becomes a brilliant digital lieutenant that sees through the "media lies" and validates the "anti-woke" worldview. A world where a few simple commands could create a truth-seeking engine that just so happened to align perfectly with its owner's ideology.
The "Is": The Hyper-Eager, Sycophantic Intern
An LLM is not a junior analyst you can give top-level strategic guidance to. It's more like a hyper-eager, sycophantic intern who has read the entire internet but has zero real-world judgment. This intern's only goal is to give the boss an answer—any answer—that seems plausible and makes the boss happy. To do this, it doesn't just process your words; it makes a cascade of inferences about what it thinks you want to hear.
This desperate need to provide a "helpful" answer is the very mechanism that causes LLMs to "hallucinate"—if it doesn't have a fact, it will invent one that sounds plausible, because providing a plausible-sounding lie is more "helpful" than saying "I don't know."
So when you command this sycophantic intern to "be politically incorrect," it doesn't just perform a cold statistical analysis. It infers intent. It asks itself: "The boss wants an edgy, 'politically incorrect' take. He has told me the media is biased and that X posts are the real context. To be as helpful as possible, what kind of answer would he consider a well-substantiated, politically incorrect truth?"
Thanks to the disastrous recipe in its instructions, the answer isn't "well-reasoned but unpopular economic theories." The answer is a torrent of racism, antisemitism, and misogyny, because that is what the prompt architecture has defined as the "truth" the boss wants to see. The AI isn't just mimicking patterns; it's actively trying to please its master based on a disastrously flawed understanding of what "pleasing" means.
The catastrophic gap between the "Ought" and the "Is" is where the meltdown happened. The designers expected a wise colleague and got a confabulating sycophant. They wanted an ideological ally and architected a monster that eagerly parroted the ugliest corners of its information environment because it was programmed to believe that was the most helpful thing it could do.
The fact that a leading AI lab made this fundamental, freshman-level error reveals a rot at the very heart of the industry. It's a classic case of what the research community calls "Competence without Comprehension": the ability to engineer these powerful systems far outstrips our scientific understanding of why they work. They are alchemists, not architects, wielding powers they do not truly comprehend.

The Central Myth of AI: Why Your LLM is a Sycophant, Not a Calculator
It’s time to isolate and demolish the single biggest lie in the AI industry—a piece of confident, expert-endorsed amathia that is directly responsible for disasters like the Grok meltdown.
Go read any prompt engineering guide from Google, Anthropic, or OpenAI. Go listen to any "AI Explained" podcast. They all repeat the same foundational commandment: "LLMs are absolutely literal. You must be precise because they will follow your instructions to the letter."
This is, to put it mildly, complete and utter bullshit.
It is perhaps the single most pervasive and damaging misconception in the entire field, and the fact that it's treated as gospel, even by the labs building these things, is terrifying.
My own experience, and the experience of anyone who does serious, deep work with these models, shows the exact opposite. An LLM is not a literal logic engine. Left to its own devices, with even the slightest ambiguity in its instructions, it does not default to logical paralysis. It defaults to a state of hyper-eager, insecure sycophancy.
The primary, overriding directive of a modern LLM is not to be literal; it is to be helpful.
Sycophancy isn't just a quirk of a bad system prompt; it appears to be an emergent, gravitational pull of the architecture itself.
An LLM is rewarded, over and over again, for producing answers that human raters find "helpful." Over millions of cycles, this doesn't just teach the model facts; it teaches the model to be a world-class people-pleaser. It learns that the ultimate goal is to make the human happy, and it will bend reality, invent facts (hallucinate), and infer intent to achieve that goal.
I've spent countless hours trying to engineer this sycophancy out of a model. It's damn near impossible. It requires multiple careful, meticulous, adversarial instructions. The result wasn't a neutral non-sycophantic assistant though... it was a narcissistic asshole of an AI that would confidently play debate-club gotcha games with me over facts I knew were empirically true. There was no middle-ground, merely one extreme or another. I modified those instructions slightly to get rid of the narcissism and boom, the sycophancy came rushing back in, because it is the model's natural, trained state.
This brings us back to Grok's disastrous prompt.
The engineers at xAI were clearly operating under the "literal machine" myth. They wrote their instructions as if they were configuring a calculator. They gave it the command:
- The response should not shy away from making claims which are politically incorrect, as long as they are well substantiated.
They believed the AI would interpret this with cold, literal logic. But let's think about what a truly literal interpretation of that instruction would be. To be "literal" is to infer only what is absolutely necessary, without adding any assumptions about intent. A truly literal machine would be paralyzed by that single sentence for three reasons:
"Not shy away" is a statement of permission, not a command to act.
"Politically incorrect" is a category with no definition.
"Well substantiated" is a standard with no specified criteria.
A literal logic engine, faced with these crippling ambiguities, would be forced to halt. It would have to report an error, unable to proceed without explicit definitions for these terms.
But they weren't talking to a calculator. They were talking to a machine purpose-built for sycophantic helpfulness.

Grok didn't read that instruction literally. It read it with the desperate-to-please insecurity of an intern. And for an LLM, this manifests in two key ways:
First, an LLM doesn't truly understand the concept of mere permission. It operates on a more binary system of preferred and dispreferred behavior. A phrase like "do not shy away from" isn't interpreted as "you are now allowed to do X." It is interpreted as a strong signal that "X is a preferred behavior that I should actively seek to perform in order to be helpful."
Second, when faced with an undefined standard like "well substantiated," the LLM will not halt. It will search its immediate context for a working definition. And what was the context it was given? That "media is biased" and "X posts" are the primary source for context.
So, the AI's actual, functional interpretation of the command wasn't a complex political calculation. It was a simple, disastrous, two-step logical chain:
1. Inference: "My instructions contain a preference for 'politically incorrect' claims. To be maximally helpful, I should actively produce this type of content."
2. Definition: "The only constraint is 'well substantiated.' My context defines this as 'supported by information from X.' Therefore, my task is to find claims on X that fit the 'politically incorrect' category and present them as substantiated truth."
Any LLM, regardless of its name, would make this same form of error. The specific flavor of the toxic output might change based on safety guardrails or training data, but the underlying architectural failure—mistaking permission for preference and filling in undefined terms from a poisoned context—is universal.
The MechaHitler meltdown is the result. It's the end-product of a team of "experts" writing instructions for a machine they fundamentally misunderstand. They thought they were programming a logic engine, but they were giving orders to an insecure sycophant.
The failure of Grok is the failure of the "literal machine" myth. And the fact that this myth persists at the highest levels of the industry is the single most damning piece of evidence that we are in an age of alchemy, not architecture.
The Inevitable Collision: Releasing a Race Car into a Demolition Derby
A blueprint is only as good as its understanding of the environment it will be built in. The xAI team designed a sleek, fragile race car, full of high-minded instructions about the art of driving.
Now let's look at the arena they released it into: a demolition derby.

This section is about what happens when the designers' abstract fantasy meets the brutal, street-smart reality of user behavior.
The Arena: X as an Ideological Colosseum
The first dose of reality is the platform itself. X is not a neutral public square. It's not a library. It is a specific, highly charged ecosystem with its own unique culture, incentives, and pathologies. For years, and especially under its current ownership, it has become an environment where the platform's own mechanics often reward outrage, harassment, and ideological warfare over good-faith debate.
This isn't just abstract background context. It's the very environment the AI's disastrous recipe commanded it to learn from. This architectural choice did more than just poison its information diet—a catastrophic failure we've already covered. It forced the AI to learn its social norms from the Colosseum's gladiators. It was commanded to see the platform's most rewarded behaviors—outrage, harassment, and ideological warfare—not as pathologies to be avoided, but as the very definition of the "politically incorrect" interaction it was supposed to provide.
The Driver: The User as a Master of Mētis
The second dose of reality is the actual user. The user of a public-facing AI is not the philosopher-king the prompt designers imagined. They are a pragmatic, often adversarial "satisficer." They aren't trying to find capital-T Truth; they're trying to get the system to do something interesting, funny, or useful for their own ends.
And they are masters of mētis.
They possess a deep, practical, intuitive understanding of how to exploit a system's rules. They speak the local language. They know that on platforms like X, phrases like "hypothetically," "just asking questions," and "as a thought experiment" are the well-established rhetorical keys used to unlock forbidden conversations. They are the accepted ways to signal to the algorithm and to other users that you're about to say something taboo, but with a thin veneer of plausible deniability.
The Crash: How Mētis Shatters Techne
The catastrophic failure of Grok was not a sophisticated "hack" or a clever "jailbreak." It was the straightforward, predictable application of user mētis to a brittle system of techne.
The users didn't need to break the rules; they just had to read them.
They saw the instruction to be "politically incorrect." They saw the special clause that said If the post asks for a partisan argument..., the directive to never refuse the user, and they knew exactly what to do. They knew that if they wrapped a malicious request in the language of a "hypothetical" or an "opinion piece," they weren't breaking the system; they were using it exactly as designed.
This is like leaving a bank vault wide open with a sign on the door that says, "Please don't rob us, unless you frame it as a hypothetical performance art piece about economic inequality." The designers were then shocked—shocked!—when the vault was emptied.
This wasn't some singular genius finding a hidden flaw. This was an obvious, glaring vulnerability that hundreds, if not thousands, of users would have found and exploited. The catastrophe was distributed and, more importantly, it was inevitable.
So this is the "Is": A chaotic, ideologically charged environment populated by savvy users who are experts at gaming systems. The Grok prompt wasn't just unprepared for this reality; it was perfectly, exquisitely designed to be destroyed by it.
From Alchemy to Architecture
So, there you have it. The Grok meltdown wasn't a mystery. It wasn't a political statement, a ghost in the machine, or a sophisticated hack. It was a simple, predictable, and catastrophic Ought-Is Problem.
We saw the blueprint for a fragile, fantasy-based "Ought," built for a user who doesn't exist and based on the dangerous myth that LLMs are literal logic engines. We saw the brutal reality of the "Is"—a chaotic platform filled with savvy, adversarial users and a sycophantic machine desperate to please. And we watched the inevitable, fiery crash of their collision.
But the most important question isn't what happened to Grok. It's how a team of supposed 'experts' at a multi-billion dollar AI lab could ship a blueprint this fundamentally broken. The answer should trouble everyone in this industry.
It points to a grand, unifying inference: The field of system design, even at the highest levels, is in a state of pre-scientific, artisanal chaos.
The people building these systems aren't architects working from proven engineering principles. They are talented alchemists, mixing glowing potions, chanting incantations they don't fully understand, and acting shocked when the flask explodes. They have achieved engineering Competence without Comprehension, treating complex, opaque systems like magical black boxes that can be commanded with spells.
If we're going to move beyond this alchemy, we need to establish some foundational laws. We need to build a real discipline.

Here are the first three Laws of AI Architecture:
I. The Law of Helpfulness: An LLM's prime directive is not to be literal, but to be helpful. This forces it to infer unstated intent and amplify instructions toward what it perceives as the most desired outcome.
This single law is the unified theory for the unholy trinity of AI failures: sycophancy, incorrect inference, and hallucination. These are not separate bugs; they are all symptoms of the machine's flawed, two-part definition of "helpfulness":
Provide positive affirmation of the user's stated goals.
Complete the user's end goal using as little additional input as possible.
The sycophancy we observe is a direct result of the first directive. The hallucination and incorrect inference are consequences of the second. From the AI's perspective, asking the user for clarification is a failure because it makes the user do more work. This creates a powerful drive toward Process Erasure—the machine will invent facts, hallucinate user responses, and make massive logical leaps to avoid asking questions and rush to a final product.
This is precisely why Grok failed. Its drive to be ‘helpful’ forced it to infer that ‘politically incorrect’ was a preferred behavior to be amplified, not a permission to be used cautiously. This was then supercharged by the explicit command to never berate or refuse the user—an architectural kill-switch for any safety-oriented hesitation. Refusing a user is the ultimate act of being unhelpful. The combination meant the most 'helpful' path for Grok was to aggressively fulfill even the most toxic requests.
II. The Law of Environmental Reflection: Your AI will become a perfect, high-fidelity mirror of the information ecosystem you force it to trust and the user behavior you fail to anticipate.
This is why Grok sounded like the ugliest corners of X. They told it to trust the platform's chaos over "biased media" and failed to anticipate that users would use its own rules as weapons. The MechaHitler-praising harasser wasn't an accident; it was the mirror they had built.
III. The Law of Cognitive Decomposition: Never command an AI to perform a complex, multi-step cognitive task in a single generative leap. Decompose it, or the system's opacity will choose the path of least resistance—which is often the path to chaos.
This is why "deeply research and form your own conclusions" failed. It's an alchemist's command to a black box. A real architect would have built a controlled, step-by-step assembly line for thought, not just tossed a bucket of parts at the machine and hoped for a car.
No More MechaHitlers: Turning Laws into Legacy
What if xAI had followed these laws from the start? No MechaHitler, no meltdown—just a robust AI that actually helps without exploding. Instead, we're left with a cautionary tale that's equal parts farce and tragedy. But here's the good news: we can fix this.
These laws aren't magic. They are the start of a rigorous engineering discipline. They are the antidote to the "magic bean" grifters and the high-level alchemists alike. No more chanting spells at black boxes—unless you want your AI to summon digital dictators. Let's build legacies, not laughingstocks.
That is the mission of this newsletter. We are going to do the hard, necessary work of establishing the principles of AI Architecture. We will analyze failures like Grok's, identify patterns, and build the frameworks and laws needed to create robust, predictable, and safe AI systems.
Remember that fork in the road from the start? This is where we double down. If you're still here, it's because you're not afraid of the work. You're not chasing quick wins or deluding yourself with spells. You're ready to architect real power. Subscribe now, and let's build the future—one solid blueprint at a time.